 Wenn Sie die Google Search Console für Ihre Website verwenden (und das sollten Sie!), dann haben Sie möglicherweise in letzter Zeit eine Nachricht erhalten mit dem Titel:
Wenn Sie die Google Search Console für Ihre Website verwenden (und das sollten Sie!), dann haben Sie möglicherweise in letzter Zeit eine Nachricht erhalten mit dem Titel:
Der Googlebot kann nicht auf CSS- und JS-Dateien auf URL zugreifen.
(Anstelle von URL wird Ihre Website genannt.)
In den meisten Fällen haben Sie der Suchmaschine mit Hilfe der Datei robots.txt verboten, sich bestimmte Dateien oder Verzeichnisse anzusehen (=> zu crawlen). Mehr Informationen zur robots.txt finden Sie in meinem Artikel Die Datei robots.txt.
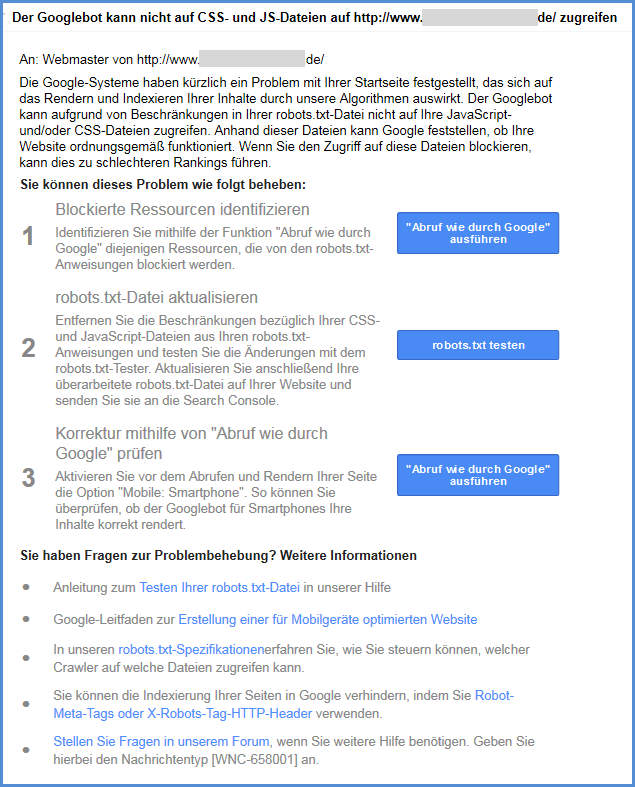
Die Meldung selber lautet:
Die Google-Systeme haben kürzlich ein Problem mit Ihrer Startseite festgestellt, das sich auf das Rendern und Indexieren Ihrer Inhalte durch unsere Algorithmen auswirkt. Der Googlebot kann aufgrund von Beschränkungen in Ihrer robots.txt-Datei nicht auf Ihre JavaScript- und/oder CSS-Dateien zugreifen. Anhand dieser Dateien kann Google feststellen, ob Ihre Website ordnungsgemäß funktioniert. Wenn Sie den Zugriff auf diese Dateien blockieren, kann dies zu schlechteren Rankings führen.
Mausklick für eine größere Darstellung
Wie Sie sehen können, werden in der E-Mail auch gleich ein paar Hinweise gegeben, wie Sie dieses Problem beheben können.
Möglicherweise schleicht sich jetzt ein Stirnrunzeln in Ihr Gesicht, denn Sie haben doch immer alles daran gesetzt, dass Google Ihre Seiten leicht finden und indexieren kann, also …
Wieso kann Google nicht auf meine Dateien zugreifen?
Früher hat Google sich nur für den reinen Text Ihrer Seite interessiert (technisch gehört der HTML-Code auch dazu). Das Design in Form von CSS und zusätzliche Programmierung in Form von JavaScript wurde nicht berücksichtigt. Beides kann aber sehr wichtig für die Bedeutung der Inhalte einer Seite sein. Die Suchmaschinen haben daher dazu gelernt und versuchen, die Seiten zunächst zu rendern (also so aufzubereiten, wie Sie als User die Seite im Browser sehen) und erst dann zu analysieren.
Natürlich ist es dazu notwendig, dass der Zugriff auf die entsprechenden Dateien nicht per robots.txt blockiert wird.
Die E-Mail von Google bedeutet allerdings nicht, dass Ihre Webseiten fehlerhaft seien. Google vermisst lediglich den Zugriff auf einige Dateien.
Welche Dateien sind für den Googlebot blockiert?
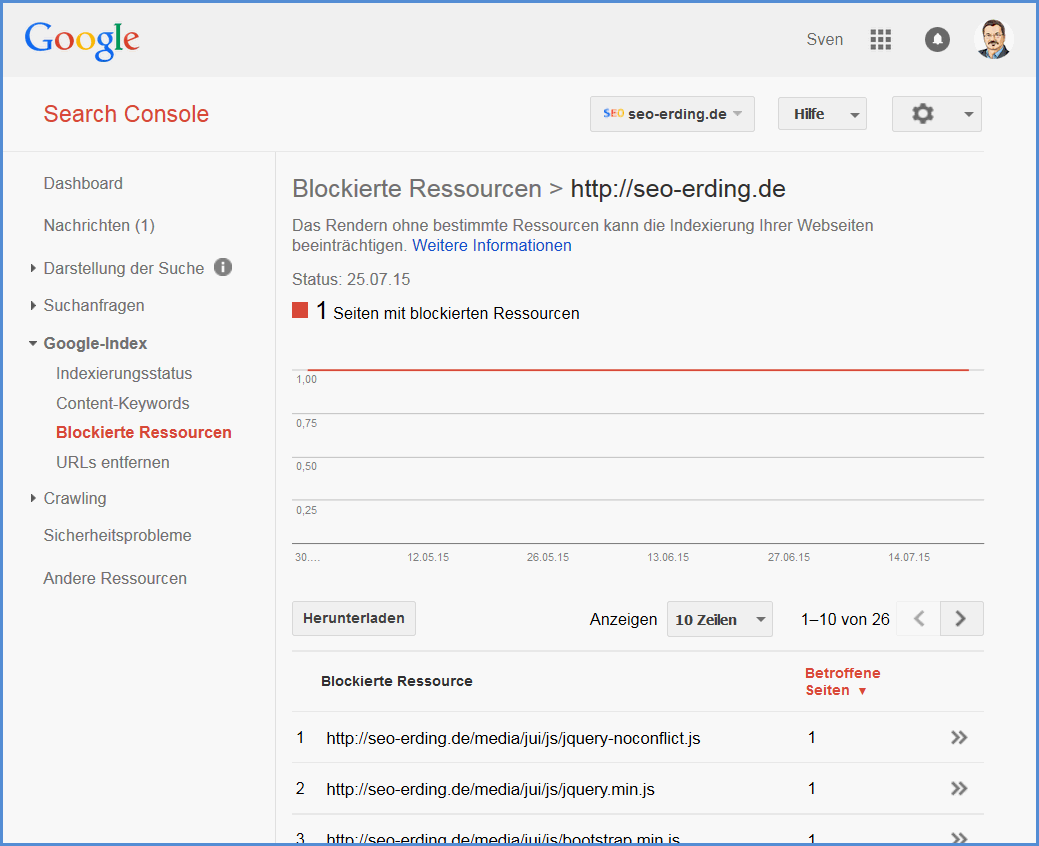
In der Google Search Console gibt es einen eigenen Menüpunkt Google-Index -> Blockierte Ressourcen, um sich die Dateien anzeigen zu lassen, auf die der Googlebot nicht zugreifen kann.
Mausklick für eine größere Darstellung
Die Liste finden Sie am unteren Ende des Screenshots als Auszug.
Zusätzlich können Sie sich die von Google gefundene robots.txt unter dem Menüpunkt Crawling -> robots.txt-Tester zur Prüfung anzeigen lassen.

Mausklick für eine größere Darstellung
Was kann ich tun?
Ganz einfach: Google darf der Zugriff auf die angemeckerten Seiten nicht verwehrt werden. Werfen Sie also einen Blick in Ihre robots.txt.
In der robots.txt sollte der Zugang auf die Themes/Template-Verzeichnisse nicht gesperrt werden.
Für WordPress wären das (beispielsweise):
- /wp-content/plugins/
- /wp-content/cache/
- /wp-content/themes/
- /wp-includes/
Standardmäßig werden in der von WordPress virtuell angelegten robots.txt nur die beiden folgenden Verzeichnisse blockiert:
- /wp-admin/
- /wp-includes/
In /wp-includes/ werden allerdings eine ganze Reihe von CSS– und JS-Dateien abgelegt, so dass es sinnvoll ist, auch dieses Verzeichnis nicht zu sperren. Dazu muss dann allerdings eine eigene physische Datei robots.txt angelegt werden.
Joomla! verwendet für Themes/Templates (beispielsweise):
- /templates/
Alle aufgeführten Verzeichnisse enthalten sowohl CSS– als auch JS-Dateien und sollten daher nicht mit einem disallow blockiert werden.
Entfernen Sie die Einträge entsprechend in der robots.txt oder machen Sie durch das Voransetzen eines # aus der Zeile einen Kommentar (in dem Fall wissen Sie später noch, welche Verzeichnisse Sie manuell von der Blockade befreit haben).
Das könnte dann folgendermaßen aussehen
# Disallow: /templates/
Falls Sie weder WordPress noch Joomla! verwenden, könnten Sie möglicherweise eine der folgenden Zeilen in Ihrer robots.txt finden, die das Rendern der Webseite verhindern:
Disallow: /*.js$
Disallow: /*.inc$
Disallow: /*.css$
Disallow: /*.php$
Auch diese Zeilen soltlen Sie entfernen oder auskommentieren.
Anders herum funktioniert es ebenfalls. Statt Google etwas nicht zu verbieten, können Sie Google den Zugriff auch explizit erlauben. Das sieht dann folgendermaßen aus:
User-agent: Googlebot
Allow: /*.js$
Allow: /*.css$
Aber Vorsicht! Die Anweisung Allow: ist offiziell nicht definiert, wird aber von einigen User-Agents (wie dem Googlebot) ausgewertet. Die Reihenfolge der Anweisungsblöcke spielt für den Googlebot in diesem Fall keine Rolle. Wenn ein Block speziell für den Googlebot definiert wird, so werden alle anderen Blöcke überlesen. Wenn Sie in Ihrem Block allerdings nichts verbieten, so wie im obigen Beispiel, dann können Sie auch gleich alles mit „Allow: /“ erlauben. Der Block macht also nur Sinn, wenn Sie zusätzlich dort Verzeichnisse oder Dateien ausschließen.
Wie kann ich meine Bemühungen überprüfen?
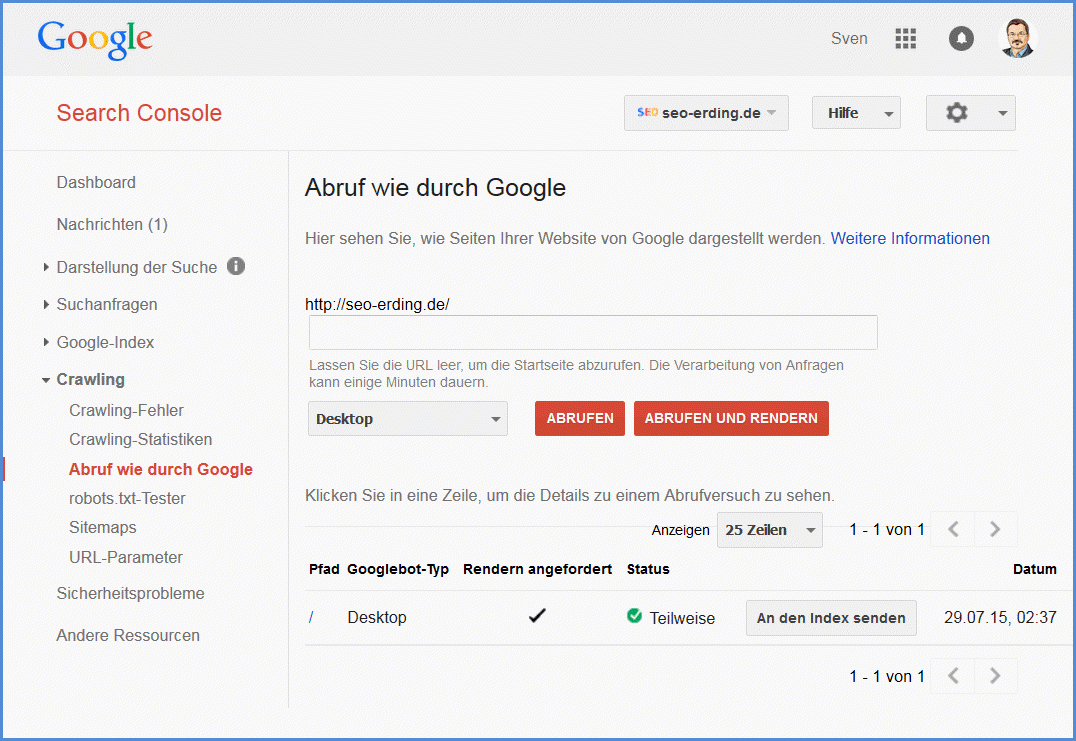
Wenn Sie Ihre robots.txt geändert haben, können Sie das Ergebnis Ihrer Bemühungen sofort in der Google Search Console überprüfen. Dazu reichen Sie Ihre Seite bei Google für einen Recrawl über den Menüpunkt Crawling -> Abruf wie durch Google ein.
Mausklick für eine größere Darstellung